Here is a post about how to enable sql cache dependency in sql 2005 http://davidhayden.com/blog/dave/archive/2006/04/29/2929.aspx
Friday, December 14, 2007
CSS classes,Elements, Element IDs, Blocks
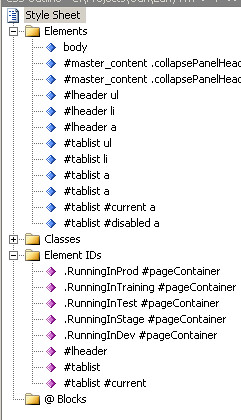
In visual studio, when you edit the CSS files, you can see the different sections which are supported by CSS. I have a couple of confusions regarding the difference between them.
- What is the difference between Element Id and Classes. Here is a good explanation about this . Format wise, A CLASS is preceded by a dot (.), and an ID with a hash mark (#), then the CLASS or ID name and the declaration. With the ID selector you identify an element to be an *unique instance* in a document. You can declare a CLASS and apply this class to all elements inside the BODY, a <p>, a <span> and a <div> multiple times within the same document, on the same page, without any problems. IDs have more weight than classes.
- What is the difference between Elements and Element IDs/Classes. The Element is another level down from the Element IDs or Classes. For example, you have a Id name tablist here.
<div id="tablist" >
<ul><li><a href="AgencyList.aspx">Agency List</a></li></ul>
<ul><li id="current"><a href="#">Agency Details</a></li></ul>
</div>You define tablist as the Element Ids, but you can further define tablist ul, tablist li as the Elements, which are kind of one level below and essentially html elements. Similarly, you can define class firstly, and then define Elements. Element apply to the intrinsic html element such as body, h1, h2, p.
Element Id ends with “#” sign, Classes end with “.” sign, and Element ends with “nothing” :-)
Thursday, November 22, 2007
Ajax UpdatePanel , GridView , CommandField
I encountered a strange problem when working with a GridView control inside an Asp.Net ajax update panel. Basically, I have a portion of code look like this
1: <asp:UpdatePanel ID="UpdatePanel1"
2: UpdateMode="Conditional"
3: runat="server">
4: <ContentTemplate>
5: 6: <asp:GridView id="dgIFSPServices" runat="server" PageSize="15" AllowPaging="True" AllowSorting="True"
7: AutoGenerateColumns="False" Font-Size="9pt" Font-Names="Arial" width="100%" IsSortedAscending="True" BorderWidth="1px" BorderStyle="Solid"
8: ForeColor="Black" DataKeyNames="IFSPServiceID" DefaultSort="StartDate" RecordCount="0" OnRowEditing="dgIFSPServices_RowEditing">
9: <Columns>
10: <asp:CommandField ButtonType="Image" EditImageUrl="../../../Images/Edit.gif" ShowCancelButton="False" ShowEditButton="True"></asp:CommandField>
11: </asp:GridView>
12: 13: </ContentTemplate>
14: </asp:UpdatePanel>
And in the code behind page,
1: protected void Page_Load(object sender, EventArgs e)
2: {3: if (!IsPostBack)
4: {5: //Only binding data when the page is loaded at the first time.
6: }7: else
8: { 9: } 10: }
Every time, when I click the edit button in the <asp:CommandField> , the Page_Load is called twice. At the first time, IsPostBack is true, and the second time, IsPostBack is false. Since I have some special code which I definitely only want to run it when the page first loads, this double loading behavior causes some unpleasant effects.
After some extensive search, I found the answer in this post. It was decided how the command field is interpreted by the asp.net and rendered in the html page. In my example, it was rendered as
1: <INPUT style="BORDER-TOP-WIDTH: 0px; BORDER-LEFT-WIDTH: 0px; BORDER-BOTTOM-WIDTH: 0px;
2: BORDER-RIGHT-WIDTH: 0px" onclick="javascript:__doPostBack('ctl00$ContentPlaceHolderBody$IFSPReviewOld$dgIFSPServices','Edit$0')"
3: type="image" alt="Edit"
4: src="http://localhost:29162/Odh.EarlyTrack.UI/Images/Edit.gif" value="" />
The input type="image" is treated as a submit button by the browser, and will load the page once with IsPostBack=false, and onclick will load the page once again with the IsPostBack=true.
There is another alternative workaround in the post, you can subclass the linkbutton class, and use the linkbutton inside a template field to achieve the same purpose without the double post.
Thursday, November 01, 2007
Web Testing
I have been helping our testers automate the test for our web applications, and right now, we are using VSTS testing and fiddler. Based on some information gathered from a post by James Avery, it seems I need check out some other options there, like WaitN, WaitN test recorder, also selenium, I guess my to do list will get much longer now.
And the biggest headache for our application is the lacking of automating testing, and since the application was developed by some other contractors originally, I am very cautions to change any code since there is no automatic verification.
Wednesday, October 31, 2007
AVIcode experience
I have been working on a project called "EarlyTrack" for the state of Ohio in the last 8 months, and the best thing I found is the "AVICode" monitoring tool installed on the production machine.
As a developer for the last 6 years, I understand that every application will have bugs in production no matter how much you test on your test environment. But when the user complains that they have ran into an issue, it is very hard to find what exactly goes wrong because of the challenge of recreating the exactly same issue. AVICode provides the exactly solutions for this kind of issue, it intercepts the exceptions thrown by the system and records very detailed information on what exactly happened in the cod when the bugs were triggered.
The most impressive thing is that if you installed the pdb(debugging database) file alongside the released binary file, every time a bug triggers, you can double click to get to the exact line of code which failed.
I'll take some screen shots later on..
C String.
There is a good article about C String, basically, there are two ways of declaring a string, either statically or dynamically.
- To declared a string statically, we can either declare an explicit number of string length or not.
1: char label1[]="I am a test!";
2: char label2[100]="I am a test!";
The length of the first string is decided by the actual string length, while the second string is explicitly declared as having the length of 100. Both of ways declare a mutable string, which is different with char* label3="I am a test!". The later one are essentially the same with const char* label3="I am a test!" . If you try to do something like lable3[0]='i', you will encounter an access violation error.
Here is a good link about this problem: Basically, when you declare char* label3="I am a test!". it will be a constant string in the data section, this string constant has always the same address and is constant. You should always consider const char* label3="I am a test!" because the former is only for backward purpose.
2. To declare a string dynamically, the string length has to be passed in like this char* dynamicalString=new string[length+1]. The last character is reserved for '\0', the end of string. The string length (strlen) is length, not length+1.
Thursday, October 11, 2007
Enterprise Library configuration.
A very good post on how to change the configuration of the enterprise library.
Wednesday, September 26, 2007
Assembly Load, LoadFrom, LoadFile
I think I am not very clear about those different loading functions, so I looked up a couple of different sources, and it helps a lot. Here are some understanding I summarized:
- If possible, it's better to call Load instead of LoadFrom since the later has to call the first anyway.
- LoadFrom actually calls the Load method: Internally, LoadFrom will firstly try to get the AssemblyName by call System.Reflection.AssemblyName.GetAssemblyName( path) method, then it will call Assembly's Load method, passing it the AssemblyName object. If load fails to find an assembly, then LoadFrom loads the assembly at the path name specified in the LoadFrom method. It is possible that there exist two different assemblies which have the same identity, so when LoadFrom internally calls Load, it may load an assembly which is different with the path you specified in the LoadFrom.
- LoadFile will load the assembly without CLR applying any policies or searching.
- When Load looks for the assembly, it will be based on the following searching path:
- GAC
- Application's base directory.
- Private path subdirectories.
- code base locations.
- Load has two versions, one is Load(AssembyName), the other is Load(String). When you use the the second method to load, your normally pass in a string like this "mscorlib, Version=2.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089". Remember, the first section of the string is name, which doesn't include the path and extension. If you choose to use AssemblyName to load, there are three situations.
- You didn't specify the codebase, but include other bits. If you don't specify the code base, and set the AssemblyName.Name, CultureInfo, public key token / public key and/or Version properties, it's essentially the same as the Load(String), because you just parse out that string and put it in individual fields.
- You specify the codebase, not the name. The code base will have the format look like "file:///C:/WINDOWS/Microsoft.NET/Framework/v2.0.50727/mscorlib.dll", and if you set the codebase, not the name, then, it's doing the same thing as Assembly.LoadFrom() method based on that code base.
- When both are specified, then we do step 1 firstly, and if step 1 failed, we do step 2. The thing which worth noting is when you call Assembly.Load(AssemblyName) with a codepath, it does not mean the assembly will be loaded from that path.
References:
Monday, September 17, 2007
SQL Server performance tuning.
My experience tells me that if your web applications (or even the windows applications) run slower, 90 percent of the time, it's because some sql queries, stored procedures, indexes on the tables are not optimized. It's very important that you can find which query, which table are running slowly.
The book "SQL Server Query Performance Tuning Distilled" by Sajal Dam is a very good book on this topic.
- Use the sql profiler to find what queries are taking long time, but I finds out it's not very pleasant to work with the user interface of the profiler. It's especially annoying even if you click on the stop button, the events are still being logged. (The stop command sent through the user interface is taking long time because the logging thread is very busy in logging the events in the sql server. This is a typical scenario when you try to kill a thread which is in a busy while loop.) The author provides an alternative way to do this, you can use the sql profiler to create a template or open an existing template, and stop the log immediately after starting the log (You only need do this once, so it won't be too painful). You don't have to do that, this step simply helps you to prepare the sql scripts. You can use sp_trace_create, sp_trace_setevent, sp_trace_setfilter to create all the scripts manually. In the profiler, you can script the trace definition and the step to run the trace to a SQL script file by selecting File->Script Trace -> For SQL Server 2000.
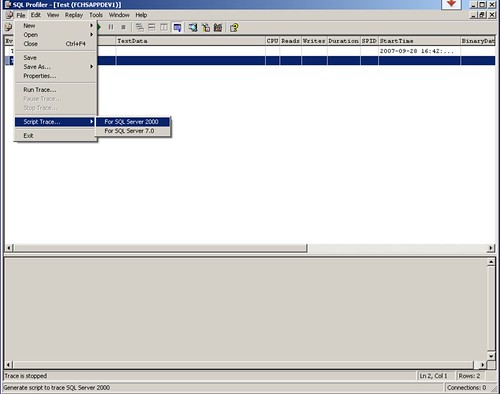
- Open the saved script file in Query Analyzer, and modify the InsertFileNameHere parameter of sp_trace_create to a meaningful filename.
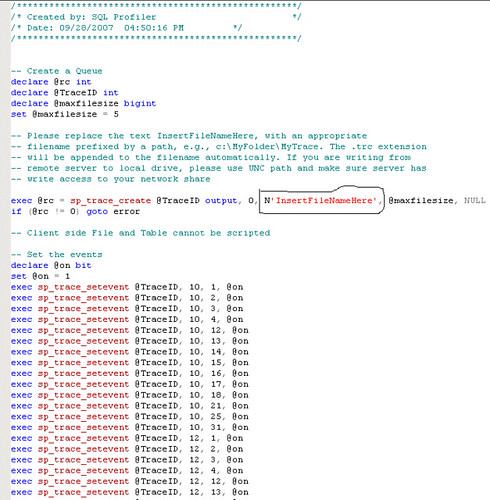
- Execute the sql script, which will start the SQL trace as a background process. It also returns the ID of the trace as traceid, which is very important and required to stop the trace later on. You can use the SELECT * FROM ::fn_trace_getinfo(default) to find the trace status.
- Use EXEC sp_trace_setstatus traceid, 0 to stop the trace and EXEC sp_trace_setstatus 1,2 to close the trace.
- Open the trace log file in the profiler and save it to a table, and you can query the cpu time, logical read, or anything else you selected in the profiling process.
Saturday, August 25, 2007
Pass by value or Pass by reference
Here is a simple example of parameter passing in C#..
1: public class ParameterPassingSample
2: {3: public ParameterPassingSample()
4: { 5: } 6: 7: public void CallingMethod()
8: {9: StringBuilder sb1 = new StringBuilder("Test");
10: CalledMethod(sb1);11: System.Diagnostics.Debug.Assert("Test test"==sb1.ToString(),"String equal");
12: } 13: 14: public void CalledMethod(StringBuilder sb2)
15: {16: sb2.Append(" test");
17: } 18: }Since CalledMethod function changed the sb value, it will easily give you an impression that Parameter is passed by reference. Actually, it's not.
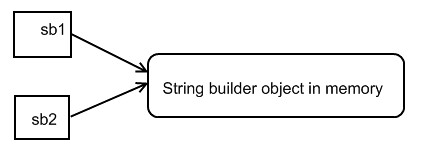
Sb2 is a new string builder object, and it points to the same string builder object in memory. So, when CalledMethod change the value, the value which the original string object (sb1) refers also change. This doesn't mean "pass by reference", it is still "pass by value". Here is another example to show this.
1: public class ParameterPassingSample
2: {3: public ParameterPassingSample()
4: { 5: } 6: 7: public void CallingMethod()
8: {9: StringBuilder sb1 = new StringBuilder("Test");
10: CalledMethod(sb1);11: System.Diagnostics.Debug.Assert("Test"==sb1.ToString(),"String equal");
12: } 13: 14: public void CalledMethod(StringBuilder sb2)
15: {16: sb2 = null;
17: } 18: }Here , if sb2 changes to null, it doesn't affect the value of sb1.
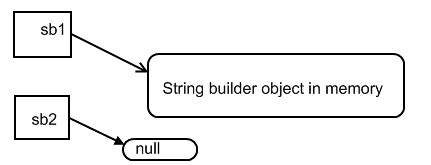
The difference between those two examples are "change the value the parameter points to" or "change the value of the parameter itself".
Monday, August 20, 2007
What are the overhead fields when you create an object in CLR
In CLR, each object has two overhead fields: a type object pointer and a sync block index.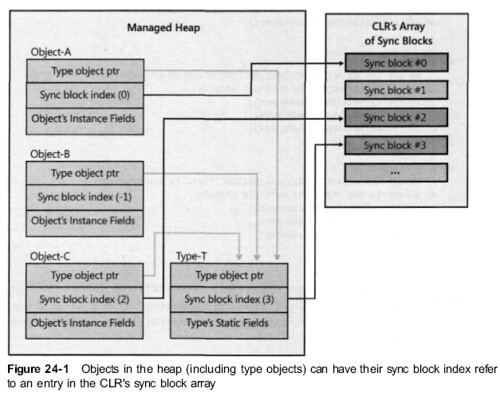
Each of the fields requires 32 bits, adding 8 bytes to each object.
WaitHandle hierarchy
Here is a reflector screenshot of the relationships among the different synchronization object. The wait handle is a simple class whose sole purpose is to wrap a windows kernel object.
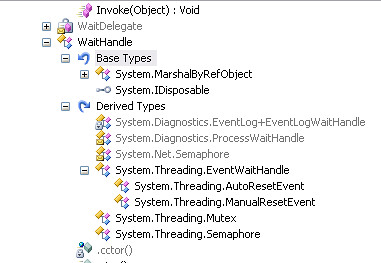
As you can see, EventWaitHandle, Mutex, and Semaphore are all inheriting from the wait handle object. When a thread is waiting on the kernel object, the thread must always transition from the user mode to the kernel mode, causing the thread to incur a performance hit. So if you want to do the thread synchronization inside an AppDomain, it's best that you simply use the Monitor, which is much more efficient than the kernel object. However, if you have to do the synchronization between different appdomains, processes, you have to use those windows kernel objects.
Saturday, August 18, 2007
Thread from the thread pool or dedicated thread.
Use thread from the thread pool to execute some asynchronous task instead of a dedicated thread can save the resources needed to create that dedicated thread.
A dedicated thread is only needed if the thread needs to run in a special priority, since all the threads from the thread pool are running in the normal priority, and you don't have access to change the priority for the thread in the thread pool.
Another reason is that if the thread needs to be run in foreground, a dedicated thread is also needed since all the threads in the thread pool are running in the background.
If the task is taking extremely long time to finish, then a dedicated thread is also needed because it is a little bit challenging for the thread pool to figure out whether to create additional thread when that task is running.
Friday, August 17, 2007
Why do you want to explicit declare an event.
In C#, you can simply declare an event by using this line :
public event EventHandler<EventArgs> MyImplicitEvent;
It's simple. But under the hood, the compiler did a lot of things for you. The line above will be translated into the
1: // 1. A PRIVATE delegate field that is initialized to nullprivate
2: EventHandler<EventArgs> MyImplicitEvent = null;
3: // 2. A PUBLIC add_Xxx method (where xxx is the Event name)
4: // Allows objects to register interest in the event.
5: [MethodImpl(MethodImplOptions.Synchronized)]6: public void add_MyImplicitEvent(EventHandler<EventArgs> value)
7: { 8: MyImplicitEvent = (EventHandler<EventArgs>)9: Delegate.Combine(MyImplicitEvent, value);
10: }11: // 3. A PUBLIC remove_Xxx method (where Xxx is the Event name)
12: // Allows objects to unregister interest in the event.
13: [MethodImpl(MethodImplOptions.Synchronized)]14: public void remove_MyImplicitEvent(EventHandler<EventArgs> value)
15: {16: MyImplicitEvent = (EventHandler<EventArgs>)Delegate.Remove(MyImplicitEvent, value);
17: }So, the compiler will inject the MethodImplOptions.Synchronized attribute into the add_ and remove_ method. By default, those methods implement the synchronization using the object itself as the the thread-synchronization lock. However, this object is public, and you shouldn't use this object to do the synchronization. Because the malicious code could use this public object to deadlock threads that use this instance of object.
A better way to handle this to do the parts which compiler generated for you by yourself. like this.
1: // Private instance field created to serve as thread synchronization lock
2: private readonly object m_eventLock = new Object();
3: // Add private field that refers to the head of the delegate list
4: private EventHandler<EventArgs> _myImplicitEvent;
5: // Add an event member to the class
6: public event EventHandler<EventArgs> ImplicitEvent
7: { // Explicitly implement the 'add' method
8: add 9: { 10: // Take the private lock and add a handler
11: // (passed as 'value') to the delegate list
12: lock (m_eventLock) { _myImplicitEvent += value; }
13: } 14: // Explicitly implement the 'remove' method
15: remove 16: { 17: // Take the private lock and remove a handler
18: // (passed as 'value') from the delegate list
19: lock (m_eventLock) { _myImplicitEvent -= value; }
20: } 21: }This way, you use the private object m_event Lock to do the synchronization, and you can avoid the problem (code outside of the class will have access to the synchronization object) compiler generated codes have.
Sunday, August 12, 2007
Paint.Net
I used the Paint.Net to edit a couple of images today when I tried to edit the html template for my blog. I want to widen the content area, and have to edit a couple of gif files.
I have downloaded the paint.net before, but really didn't try it too much. It took me some time to get used to all those concepts if you haven't used any image editing software, but I have to admit it's a really powerful image editing tools if you cannot afford the expensive adobe Photoshop.
Changed the default blog template.
One thing I don't like the blogger is the limited selection of template. I am happy with the one I selected right now, but it gave too much margin to the sidebar, and leave main content area very thin. While it's fine at most times, I did run into a couple of awkward situations when I have to insert some images into the blogger. I have to resize the image to fit into the content area.
I start to play with the html templates codes, and a couple of places I have to edit are :
#outer-wrapper {
width: 947px; (change from 847 px to 947 px)
margin: 0px auto 0;
text-align: left;
font: $bodyfont;
background: url(http://jianweisun.com/tile.gif) repeat-y; I also have to edit the original tile.gif to make it wider.
}
){kind=link}
#content-wrapper {
margin-left: 42px; /* to avoid the border image */
width: 863px; (change from 763px to 863px)
}
#main {
float: left;
width: 560px; (change from 460px to 560px)
margin: 20px 0 0 0;
padding: 0 0 0 1em;
line-height: 1.5em;
word-wrap: break-word; /* fix for long text breaking sidebar float in IE */
overflow: hidden; /* fix for long non-text content breaking IE sidebar float */
}
#header-wrapper {
width: 947px; (Add this line)
margin: 0;
padding: 0;
font: $pagetitlefont;
background: #e0e0e0 url(http://jianweisun.com/top_div_blue_947.gif) This image is also needed to be widened.
no-repeat 0px 0px;
}
{kind=link}
#header {
width: 863px; (Add this line)
margin: 0;
padding: 25px 60px 35px 60px;
color: $pagetitlecolor;
background: url(http://www.blogblog.com/tictac_blue/top_h1.gif) no-repeat bottom left;
}
){kind=link}
It looks pretty easy, but it takes me a couple of hours to figure out all those tricks.
Tuesday, July 10, 2007
Make the safe update in asp.net project.
When a project gets complicated, it become increasingly challenging to make any updates to it, especially for the project which you didn't start to work with. I was put into such a situation recently. The clients require that I make a lot of changes to an existing web applications, and they want all the new features I develop will be turned on a specific day. They also want to have the option to turn all the new features off and keep the original state.
If it's all business logic changing wrapped in a dll, it should be much easier. The challenges are that the project also involves a lot of user interface changes. If I try to make the individual element or control on a page visible/invisible based on certain conditions, it will become very messy and difficult to maintain in the future. For example, if the clients want to completely get rid of all the old features, leaving all those checking codes there will be very confusing for the people who will work on the projects in the future.
I end up putting all the old features on a page into a user control, and all my new improvements combined with the original codes in another user control like the following
In the code behind, I can swap between the old codes and new codes by setting one user control visible and the other invisible. And in the future, when the clients don't want the old features anymore, the old codes can be completely taken out.
Monday, June 25, 2007
Dict.cn
I have been using this English-Chinese dictionary website for a while, and I am really amazed with all the functionalities it provides. Traditionally, if you look up a word in the dictionary, you may forget it in the next day and have to look it up again, and the dict.cn allows you to save all your unfamiliar words into the profile. This is particular useful if you are in a learning process, you can always come back to review the words you have marked before.
Another impressive feature is that the site has collected all the words for a particular subject, say, if you want to review all the GMAT words, you can go there and review that particular subject:

When you review a particular test, you can track all your progress in your profile, this is very cool..
I have been using this English-Chinese dictionary website for a while, and I am really amazed with all the functionalities it provides. Traditionally, if you look up a word in the dictionary, you may forget it in the next day and have to look it up again, and the dict.cn allows you to save all your unfamiliar words into the profile. This is particular useful if you are in a learning process, you can always come back to review the words you have marked before.
Another impressive feature is that the site has collected all the words for a particular subject, say, if you want to review all the GMAT words, you can go there and review that particular subject:
When you review a particular test, you can track all your progress in your profile, this is very cool..
Thursday, May 17, 2007
SQL Reporting Service could get a little bit frustrated. (Invalid Object about temporary table.)
I am starting to use the SQL reporting service to generate a couple of reports for the project I am working on right now, and it could get a little bit frustrated for a newbie.
In my process, I need to generate a report based on a stored procedure.
Then, I got the following error which complains that the temporary table is invalid.
What you can do, the temporary table should be perfectly fine in the stored procedure. I just clicked OK.
Since the dataset was not generated successfully, it won’t automatically generate a list of report parameters for you.
The good thing is that unlike Crystal report which the underlying format is in binary, sql report is all xml based, which gives a lot of flexibility in editing the report manually.
You can simply manually add a list of report parameters like this in the rdl file (open it in any text editing software).
<ReportParameters>
<ReportParameter Name="countyID">
<DataType>String</DataType>
<DefaultValue>
<Values>
<Value>e12b5415-de73-4751-b2cb-2e98740c4460</Value>
</Values>
</DefaultValue>
<Prompt>County ID</Prompt>
</ReportParameter>
<--- other report parameters>
</ReportParameters>
This will generate a list of report parameters
But how do you pass those reporting parameters to the sql query parameters. If you put a table control on the report, and set the underlying data source to the previous dataset, and try to preview it. It will give you another error like this:
There are two ways to address this issue:
one way is that you go back to the dataset, set the Parameters manually there.
The other option is that you can still edit in the xml file, which is the way I preferred. Under the DataSets, looking for the DataSet interested, and set the QueryParameters there…
<DataSets>
<DataSet Name="ComplianceMissing">
<Query>
<DataSourceName>EarlyTrack</DataSourceName>
<CommandType>StoredProcedure</CommandType>
<CommandText>rptGetComplianceMissingChild</CommandText>
<QueryParameters>
<QueryParameter Name="@countyID">
</QueryParameter>
</QueryParameters>
</Query>
</DataSet>
</DataSets>
The whole process is not that trival…
Integrate Visual Studio 2003 with the Team Foundation Server Process
The Team foundation server is release by Microsoft after Visual studio 2003, so the visual studio 2003 has to go through a couple of manual configuration process to be able to work with Team Foundation Server.
Download “Visual Studio 2005 Team Foundation Server MSSCCI Provider” from Microsoft Website. (The download link could change in the future, it’s best to download a copy and store it on some place on the server).
The prerequisite to this installation is that you must already have:
Visual Studio 2005 Team Foundation Server
Visual Studio 2005 Team Explorer
.NET Framework 2.0
If you already work with Team Foundation Server with the Visual Studio 2005, you should already have those program installed.
To add an existing project to the Team Foundation Server, Right Click the Solution you want to add to the Team Foundation Server, and click “Add solution to source control”.
Select the Tfs server you want to connect to: (If it’s the first time you connect to the Tfs server, you have to type in the Tfs server name you want to connect to.)
Add the project to the Tfs Server.
After adding the project, you can see all the icons turned to “checked in” status.
You can also go to File -> Source Control to add an existing project to the solution.
Saturday, May 05, 2007
What Http Modules are configured in the machine.config .
I am looking into an issue what happens if you forgot to put any session configuration in the web.config file. The session state is one of the http modules configured in the machine.config file, there are a few besides the session state module. The following is what I found in my machine.config file.
<httpModules>
<add name="OutputCache" type="System.Web.Caching.OutputCacheModule" />
<add name="Session" type="System.Web.SessionState.SessionStateModule" />
<add name="WindowsAuthentication" type="System.Web.Security.WindowsAuthenticationModule" />
<add name="FormsAuthentication" type="System.Web.Security.FormsAuthenticationModule" />
<add name="PassportAuthentication" type="System.Web.Security.PassportAuthenticationModule" />
<add name="RoleManager" type="System.Web.Security.RoleManagerModule" />
<add name="UrlAuthorization" type="System.Web.Security.UrlAuthorizationModule" />
<add name="FileAuthorization" type="System.Web.Security.FileAuthorizationModule" />
<add name="AnonymousIdentification" type="System.Web.Security.AnonymousIdentificationModule" />
<add name="Profile" type="System.Web.Profile.ProfileModule" />
<add name="ErrorHandlerModule" type="System.Web.Mobile.ErrorHandlerModule, System.Web.Mobile, Version=2.0.0.0, Culture=neutral, PublicKeyToken=b03f5f7f11d50a3a" />
</httpModules>
Basically, when the Http application starts, it will loop through all the http modules which are configured.
And SessionStateModule is one of them, and if you look into what SessionStateModule.Init() actually does. which in turn will call InitModuleFromConfig.

Notice that SessionStateSection config = RuntimeConfig.GetAppConfig().SessionState;
And here is what it does in RuntimeConfig.GetAppConfig().SessionState.
Here is what it actually tried to read the section from "system.web/sessionState", but what if this section is missing, it will default all its values to default value of SessionStateSeciton. This is just my guessing, I tried to verify it through reflector, but the code is kind of confusing to me. When you cannot step through the code through debugger, you can only step through your code through your head. It becomes a little bit confusing..
Here is what I see the SessionStateSection in the reflector..

I am looking into an issue what happens if you forgot to put any session configuration in the web.config file. The session state is one of the http modules configured in the machine.config file, there are a few besides the session state module. The following is what I found in my machine.config file.
<httpModules>
<add name="OutputCache" type="System.Web.Caching.OutputCacheModule" />
<add name="Session" type="System.Web.SessionState.SessionStateModule" />
<add name="WindowsAuthentication" type="System.Web.Security.WindowsAuthenticationModule" />
<add name="FormsAuthentication" type="System.Web.Security.FormsAuthenticationModule" />
<add name="PassportAuthentication" type="System.Web.Security.PassportAuthenticationModule" />
<add name="RoleManager" type="System.Web.Security.RoleManagerModule" />
<add name="UrlAuthorization" type="System.Web.Security.UrlAuthorizationModule" />
<add name="FileAuthorization" type="System.Web.Security.FileAuthorizationModule" />
<add name="AnonymousIdentification" type="System.Web.Security.AnonymousIdentificationModule" />
<add name="Profile" type="System.Web.Profile.ProfileModule" />
<add name="ErrorHandlerModule" type="System.Web.Mobile.ErrorHandlerModule, System.Web.Mobile, Version=2.0.0.0, Culture=neutral, PublicKeyToken=b03f5f7f11d50a3a" />
</httpModules>
Basically, when the Http application starts, it will loop through all the http modules which are configured.
And SessionStateModule is one of them, and if you look into what SessionStateModule.Init() actually does. which in turn will call InitModuleFromConfig.
Notice that SessionStateSection config = RuntimeConfig.GetAppConfig().SessionState;
And here is what it does in RuntimeConfig.GetAppConfig().SessionState.
internal SessionStateSection SessionState |
Here is what I see the SessionStateSection in the reflector..
Subscribe to:
Comments (Atom)